阅读:0
听报道
导读:塔勒布可能是金融行业最伟大的作者,他写过好几本让人深思的好书,从《黑天鹅》、《反脆弱》、到《非对称风险》。今年塔勒布又出了一本新书《Statistical Consequences of Fat Tails》。这本书非常硬核,我们的志愿者戴国晨在通篇读完之后,结合了他自己的理解做了非常深度的读书笔记。
戴国晨是杰晶维基公益翻译计划的第一位志愿者戴国晨,远在大洋彼岸,他已经利用闲暇时间翻译了十余篇重磅,同样为杰晶推荐了无数好文章,在此表示衷心感谢!
戴国晨说:“整体读完对我帮助很大,结合之前听他上课时候的内容有豁然开朗的感觉,书里面包含了对肥尾分布不同角度的分析理解。我没有直接做翻译,而是采用笔记的形式。一来是塔勒布老师的文字本身比较晦涩,二是塔勒布老师在量化领域深耕多年,里面有一些数学炫技的成分,我尽可能的对内容做了一些简化。在术的层面上这是一本很有价值的书,通过里面的期权部分我大概能猜出Universa尾部对冲策略的超额收益来源···”
文章来源 | Statistical Consequences of Fat Tails
译者戴国晨导读:随机性是我们所生活世界的本质属性之一,身体健康情况,股票市场收益,经济增长……一系列的未来状态都可以用随机变量抽象表示。在以《黑天鹅》为代表的INCERTO系列中,塔勒布从哲学的角度对随机性进行了探讨,这部《肥尾分布的统计效应》则更进一层,从数学角度出发,对不同分布的统计性质进行了系统性研究。
面对随机性事件,人们可能面对的风险有如下几种(1)不知道分布的类型和性质(2)知道分布的类型和性质,错误的估计了参数(3)黑天鹅。
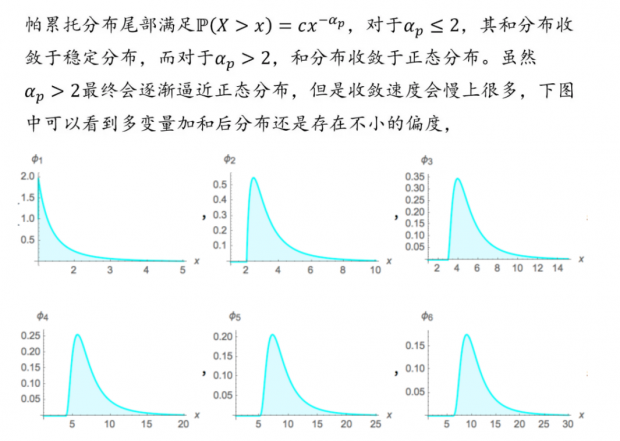
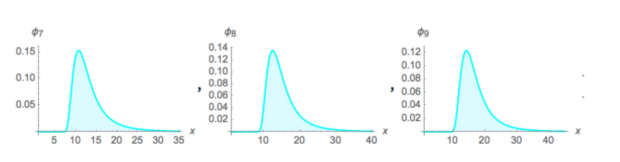
对于(1),如果错误理解了分布类型,结果很可能是灾难性的。比如估计分布为正态分布(薄尾),极端情况下的波动可能就是3个标准差的事件,但是幂律分布(肥尾)同样的概率可以出现10个标准差的事件,如果尾部进一步加厚,对数帕累托分布下同样的概率可以出现100个“标准差”的事件。不同分布对大数定律和中心极限定理的收敛性质有很大区别,因此体系的第一层是了解不同的分布,明确各自的统计性质。
对于(2),如果已经可以判断分布的类型,比如幂律分布(肥尾),但是由于样本量有限,很可能因为真正的尾部没有出现而导致分布参数估计错误,其后果同样是灾难性的。如果想要在小样本下决策,现有的统计性质就需要对“看不见的尾”进行修正,此为体系的第二层。
本书的价值正是建立这样一套体系,通过技术手段解决(1)和(2),使我们能用数学框架来认识随机性事件,并合理度量其尾部效应。这里塔勒布创造性的提出了中数视角,在小样本下大数定律尚未起作用之时,定量化描述了不同分布呈现出的统计特征。
当然(3)是永远无法量化的,不是受困于技术,而是受制于逻辑。火鸡也许可以预测每天早上食物的多寡,但不可能预测感恩节的到来,所有的数学分布和统计估计依然是经验框架下的产物。
认知真相无比之难,经验之外不可知的那一部分总是让人寝食难安,此时应该如何应对呢?塔勒布的哲学拨云见日:反脆弱,不用做预测大师,只需要改变赔付关系即可。在黑天鹅降临之时,具备反脆弱特性的事物不但不会受损,反而还能有巨大收获。
那既然有哲学妙法从根本上化解风险,为什么我们还要挖空心思在处理(1)(2)的量化技术中精进?因为反脆弱的道和数学框架的术并不是割裂的,想要实践反脆弱哲学改变赔付关系,首先要明确改变赔付的成本,追根溯源则需要对肥尾分布有定量化的理解。因此在本书的上半部分让我们先聚焦数学,深入理解肥尾效应。
— 第一部分 序言 —
了解世界越是浅薄,决策越是轻易
我们生活的世界极度复杂,充斥着不透明和不确定性,但是人们却对如何理解和应对极端不确定性少有研究。在承受巨大风险的同时,却又笼统的把罕见的事件归为一类,套用“黑天鹅”和“肥尾”来进行解释。这里的谬误在于(1) 黑天鹅代表完全超出经验框架的事件,罕见事件仍有经验可依不属于此范畴。(2) 知晓肥尾概念和真正了解其统计效应之间仍然存在鸿沟,在不同类型的肥尾下人们所面临的冲击有天壤之别,只有真正去了解尾部性质,差异化的采取保护措施才能有效管理风险。
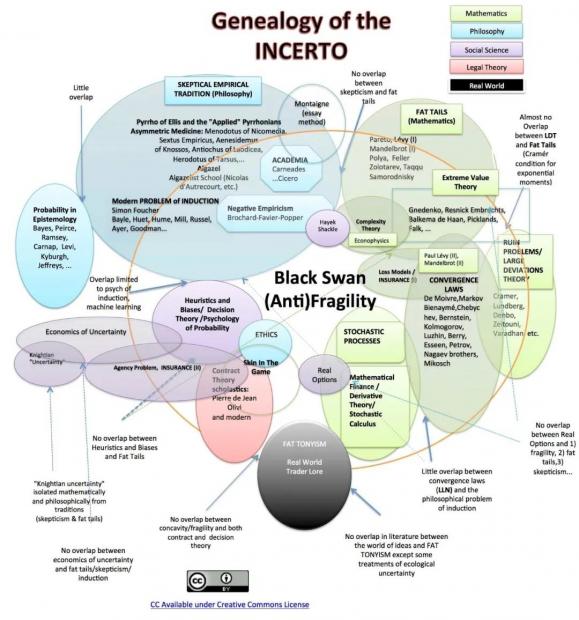
塔勒布的哲学思想包含一整套对尾部风险的认知框架,命名为INCERTO(意大利语中为不确定性)。从极端风险的道到期权交易的术,当真正踏入市场成为利益攸关的风险接受者时,就会一层层看到其中的玄妙。
INCERTO横跨五个与极端尾部风险相关的领域:数学,哲学,社会科学,契约论和决策论,目的在于探究尾部风险与现实世界的联系。其中契约论主要结合期权,决策论讨论如何保护自身甚至反脆弱。该书《肥尾分布的统计效应》为INCERTO数量化研究中的一部分,主要集合了一些研究论文和对学界的犀利批判。
INCERTO系列丛书 (2001-2018)
随机漫步的傻瓜FOOLED BY RANDOMNESS
黑天鹅THE BLACK SWAN
普洛克路斯忒斯之床THE BED OF PROCRUSTES
反脆弱ANTIFRAGILE
利益攸关SKIN IN THE GAME
INCERTO谱系
— 第二部分 词汇表 —

— 第三部分 肥尾效应简介 —
为了衡量我们所面对的尾部,可以定义平均斯坦和极端斯坦如下:
①平均斯坦(薄尾)
当样本量变大时,单一观测值无法改变整体统计属性
随机变量连续两次大于X的概率高于一次大于2X的概率
如果市场在两天内下跌了30%,很可能是每天下跌10%-20%
服从平均斯坦的分布:正态分布,身高分布
②极端斯坦(肥尾)
尾部的小概率事件会极大影响整体统计性质
随机变量连续两次大于X的概率小于一次大于2X的概率
如果市场在两天内下跌了30%,很可能是一天-29%,一天-1%
服从极端斯坦的分布:财富分布,灾难分布
灾难原则
平均斯坦中保险合约才能被合理定价,永远不要在极端斯坦下卖保险,因为基于历史赔付定出的保费很可能不够。
平均斯坦中的灾难是“好事”(可控且能帮助人们完善对分布的认知),极端斯坦中灾难是坏事(可能直接摧毁一切),举例对比不同环境中的两种灾难事件(1)某架飞机失事会导致机组人员丧生和(2)某架飞机失事会导致所有坐过飞机的人丧生,前者可以帮助飞机制造商和保险公司评估飞机失事概率,并作出改进,但后者的破坏力量太大,可能会导致人类灭亡。因此对于前一种事件,我们的目标是如何降低发生概率。而对后一种事件我们不算概率,目标在于如何降低其影响,或是完全杜绝它发生。在金融市场中类似的两种状态是(1)出现危机会导致企业利润降低(2)出现危机会导致企业破产,甚至加剧危机的蔓延,遗憾的是后者非常常见。
肥尾分布在肥尾的同时也带来了尖峰,增大了样本出现在中心区域的概率,在小样本下给人分布更稳定的幻觉。
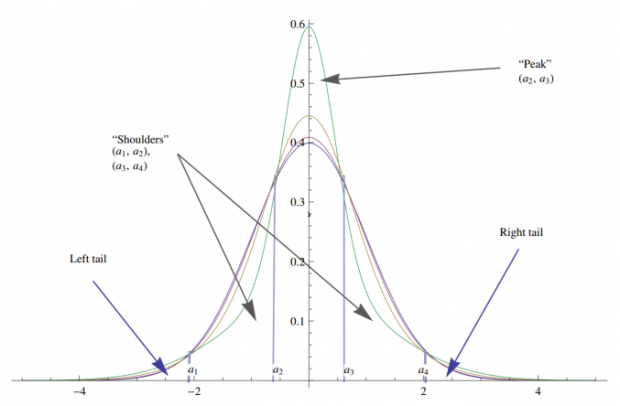
肥尾程度(不同分布由轻到重)
高斯分布
普通厚尾分布:峰度大于3
亚指数分布:灾难原则开始生效,各阶矩依然存在
幂律分布:帕累托尾部,n阶矩可能会不存在
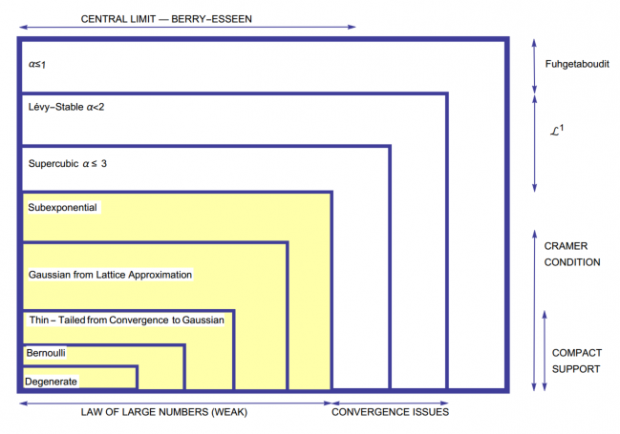
上图为分布肥尾程度表,黄色部分的分布满足大数定律,白色部分的分布尾部服从幂律,随着由内向外延伸中心极限定理逐渐失效,最后矩不再收敛。幂律尾部指数用α表示:
α≤3 超立方分布, 分布只有均值和方差,高阶矩不存在
α≤2 列维稳定分布,分布方差不再存在,只有一阶矩
α<1 Fuhgetaboudit(别整了),各阶中心矩不存在,所有过去的经验无法得出任何有意义的预示
因此在这里可以对肥尾(Fat Tail)和厚尾(Thick Tail)做一定区分。当人们讨论厚尾分布时,往往指的只是峰度大于正态的分布,但是肥尾分布对应的是“极度厚尾分布”,分布的峰度甚至都不存在,和分布也不再收敛于正态分布。
在很多学术研究中,人们明知变量满足肥尾分布的条件下,依然采用常规方法做统计检验是非常危险的,极可能因为样本量不足或是统计特征不存在而得出一些“伪结论”。
大数定律的收敛情况
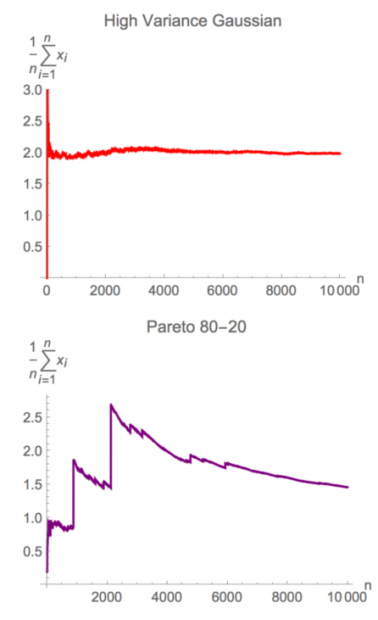
极端斯坦(下图帕累托80-20分布,α=1.13)下求样本均值收敛的速度远远慢于平均斯坦(高斯分布)。从另一个角度讲,不同分布下做统计归纳的样本量需求可能差异极大,下图给出了样本量为30时,高斯分布和肥尾分布的均值分布。
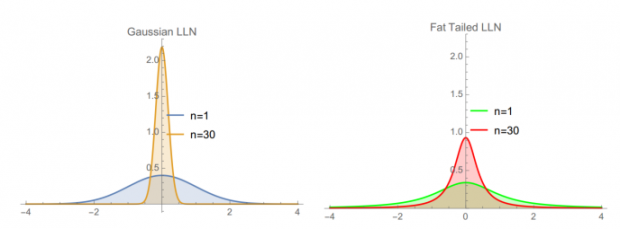
肥尾效应的一些后果
现实世界中大数定律可能有效,但是会收敛的太慢
由于样本规模的问题,样本均值一般总是会偏离分布均值,尤其是在不对称分布中
在金融领域所有的分布都是肥尾分布,一些统计量如方差和标准差并不可信,由此衍生出的beta,夏普比率,协方差矩阵等金融量也不可信。下图中的横轴为08年金融危机前对冲基金的历史夏普比率,纵轴为金融危机中的基金损失,可以看到历史波动对规避未来损失并无预测作用,在危机中很多基金出现了10个“标准差”以外的损失。
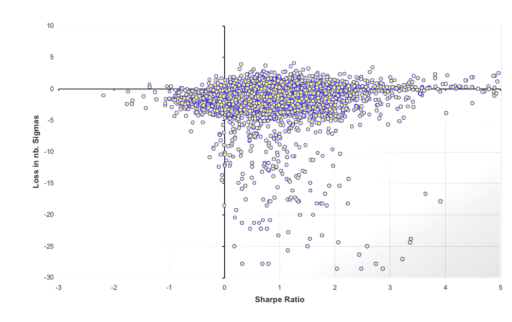
稳健统计并不稳健(修正极值会导致信息丧失),经验分布的经验有限(最糟情况会超出经验)。
最小二乘法线性回归会失效(方差不存在,小样本效应)。
即使是肥尾分布,对于一些统计量的极大似然估计依然有效,此时通过估计尾部参数α反推变量分布,再求解分布均值要比对样本直接求均值准确的多。
证实和证伪人们经验的难度比想象的要大。
主成分分析和因子分析会失效,肥尾条件下为得到稳定结果所需的样本量极大。
对样本求统计量会失效,分布的高阶矩很可能不存在,导致每个样本矩都不同且不收敛。
对极端情况下发生的损失量级很难进行估计。在高斯分布下CVAR等极端统计量还有一定意义,而肥尾分布中出现的损失可能会大到超出想象。
类似于基尼系数这样的参数不具备可加性。欧洲各个国家基尼系数的加权平均会小于整个欧洲大陆的基尼系数。其他如1%的人拥有x%的财富的指标也不具备可加性。
动态对冲无法解决期权的真正风险。
重视概率忽视赔付在肥尾条件下会导致更大的问题。现实世界中的回报并不是基于概率,而是基于赔付,但是人们在直观上更在意概率预测。一个例子是交易员预测市场上涨,但是做空市场——因为上涨空间有限而下跌空间巨大。同样的道理,一个大概率赔钱的策略不一定是糟糕的策略,只要没有破产风险且小概率能获得巨大收益即可,如尾部对冲策略(Universa);一个胜率99.99%的策略也不一定是好策略,如果不能完全规避破产风险前期盈利都会归零,如杠杆统计套利(LTCM)。
肥尾条件下对实际分布估计的微小偏离都可能带来巨大的赔付偏差。下图中的x,y轴为实际频率和预测频率,向上或向下偏离y=x分别为低估和高估。可以看到在预测概率相差不大的情况下(绿线),对α=1.15的帕累托分布进行下注,其赔付结果相距甚远(红点)。由于存在非线性关系,市场参与者的概率预测误差和最终赔付误差完全是两类分布,概率预测误差是是统计量,在0到1之间,因此误差分布是薄尾的,而赔付的误差分布是肥尾的。
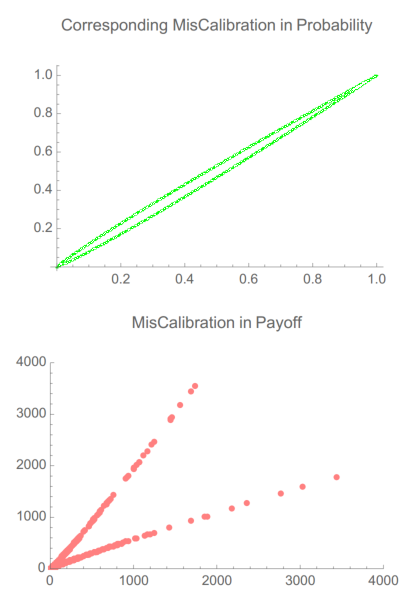
大数定律
在大数定律下,我们不断加入新的样本后均值会逐渐收敛到理论均值,但是肥尾条件下收敛速度可能会很慢,不同尾部α下收敛到同样精度所需的样本数量如下表所示。
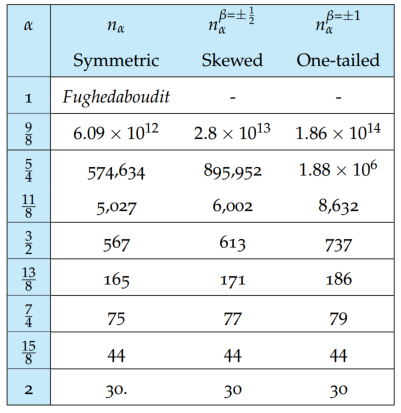
对于帕累托80/20分布,我们需要10^11量级的数据,均值才能达到正态分布30个样本的精度,也就是说在肥尾分布中,对有限的样本求均值来进行统计估计几乎毫无意义。
认识论和不对称推理
我们无法直接观察到统计分布,只能通过结果进行推测
统计分布无法保证结果与其一致
需要通过元概率来研究尾部事件
推测统计分布的难度是不对称的。罪犯装普通人比普通人装罪犯要容易得多,肥尾分布也很容易在小样本下“伪装”成薄尾分布,但薄尾分布几乎不可能呈现出肥尾特征。如果我们观测到一个20倍标准差的事件,可以确定该分布是肥尾分布,但如果没有观测到极端事件却不能确定分布为薄尾。观测到多少只白天鹅能够估计未来黑天鹅出现的概率?再大的样本都不能,而一旦出现一只黑天鹅会让认知瞬间出现巨大变动。下图中可以看到肥尾分布在灾难发生前比薄尾分布稳定的多。
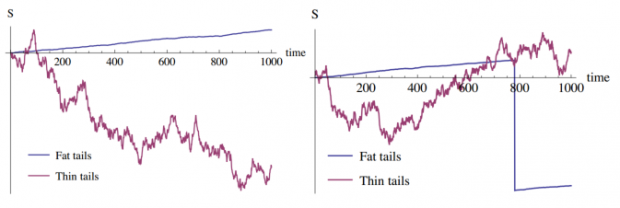
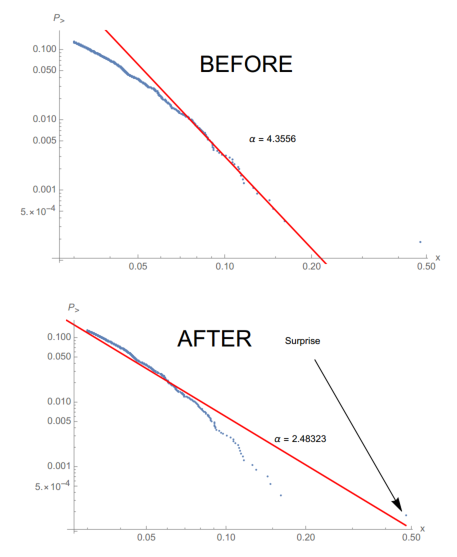
下图为阿根廷股市的表现以及2019.08.12之前和之后的回报分布,之前多年的平缓上涨隐藏了分布的真实尾部,一个单日暴跌就大幅改变了尾部alpha值(从4.35到2.48):
帕累托分布(幂律分布)
在帕累托分布下对于随机变量X和尾部值x,我们有:
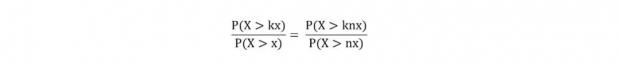
如在财富分布中,拥有2亿财富和1亿财富的人数比等于拥有2000万和1000万财富的人数比。帕累托分布没有高阶矩,因此样本统计量很不稳定。下表中展示了不同金融资产过去数十年时间序列的单日最大峰度贡献,正态分布下的单日回报峰度贡献理论值在0.8%±0.28%之间,但是标普500的结果是80%,也即整个分布峰度的80%是由一天的收益率贡献的。因此,我们从历史数据出发估计金融市场真实分布的峰度误差将会极大,四阶矩是如此,二阶矩也是如此,所有基于历史波动率和方差的模型在这里都要打一个问号。
因此肥尾分布会极大地增加求解统计量的样本量要求。在主成分分析中该影响也类似,对肥尾分布的随机变量进行主成分分析很可能会找出“伪主成分”。下图为独立正态分布随机变量在100和1000样本量下的主成分分析结果(1000个样本下主成分间的差异已经很小,较容易识别变量独立性),而下图是在100和1000样本量下,独立肥尾变量(尾部alpha=1.5)的主成分分析结果,可以看到1000样本量下依然存在着显著的“伪主成分”。
统计量估计
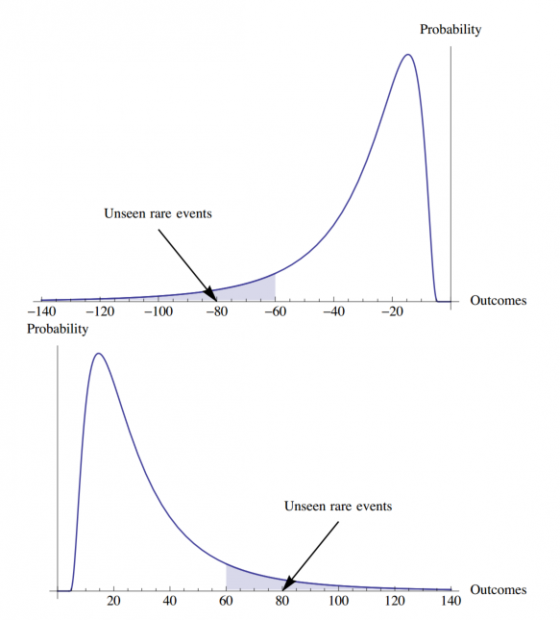
对于肥尾分布的样本来说,由于(1)肥尾事件很少发生(2)分布不一定对称,简单求样本平均估计均值的方法不再有效。一个比较好的办法是先推测分布,再从分布反求均值(极大似然估计)。比如对于帕累托分布,98%的样本会小于均值。如下图所示,阴影部分的尾部值在小样本中很可能不会出现,但是会极大影响整体均值。
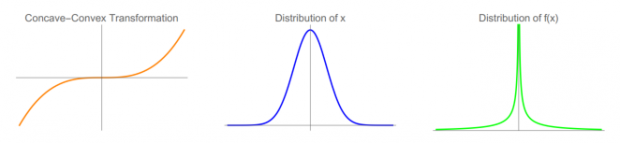
非线性影响,脆弱与反脆弱
如果把金融产品的回报看做是随机变量X,该回报施加到个人身上的影响就是F(X),X和F(X)大概率不是线性的,让潜在的非线性结果对我们有利,或者至少不对我们有害是反脆弱的必要条件。比如下列几种情况:
X是失业率,F_1 (X)是对货币基金组织的影响,F_2 (X)是对退休老年人的影响(薄尾)
X是股票价格,F(X)是你买的期权赔付(有利肥尾)
X是财富变化,F(X)是财富变化对你行为的影响(薄尾)
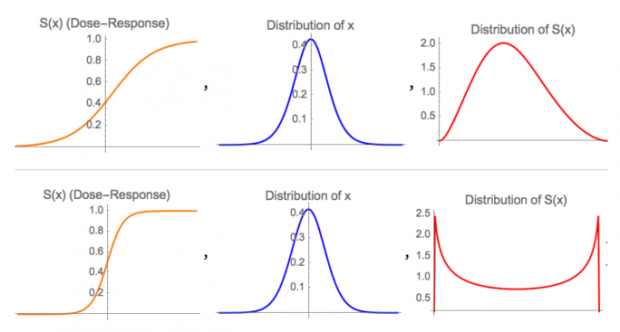
在真实世界中我们往往无法控制或是估计随机变量X的表现,但是我们可以在一定程度上选择F(X),有时甚至可以完全决定F(X)。其要点在于选择函数F(X)尾部的凹凸性,下图为同样的高斯分布经过尾部凹凸性不同的F(X)变换后成为薄尾分布(1)(2)和肥尾分布(3)
在金融市场中的一个例子是方差互换合约(Variance Swap,波动率衍生品之一),押注市场的波动率稳定就是一个脆弱状态,每次的赔付可以简化为F(X)=1-X^2,如下图所示:
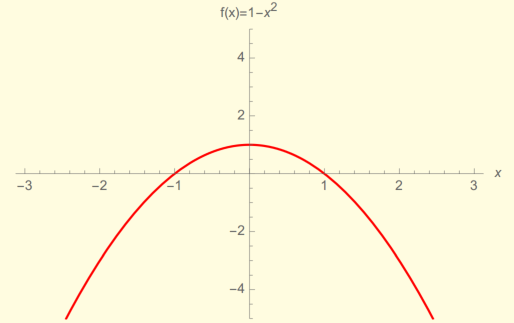
假设7次连续押注下的两种结果:
X为1, 1, 1, 1, 1, 0, 0,X均值为0.71,赔付F(X)为2(盈利)
X为0, 0, 0, 0, 0, 0, 5,X均值也为0.71,但赔付F(X)为-18(破产)
从期望的角度上来说,两者都押注了正确的方向,但是由于薄尾/肥尾分布假设和非线性尾部赔付,导致了交易结果的巨大差异。
破产和路径依赖
因为存在破产事件,财富这一变量在时间维度上存在路径依赖。对于赌场来说,每个人在场内下注是独立的,大数定律最终会起作用,而对于赌客来说,财富会依赖过去的路径,哪怕期望为正,一旦破产游戏就截断了。人们往往只重视灾难单次发生的小概率,但忽略了在重复游戏中风险会不断累积,只有在将破产风险严格控制为零,才能让自身在长期得以存活。如巴菲特左轮手枪的例子,子弹只一发,在头上开一枪可以获得100万美元,是否值得参与这样的游戏呢?可能有人会愿意为了钱冒险,但是对于成功的风险管理者来说,只要有归零风险就不应该参与游戏。
决策方法论
决策的三要素(1)观察我们所处的环境是平均斯坦还是极端斯坦(2)观察我们面对的事件是否存在路径依赖(3)考量该事件对我们的影响,脆弱或是反脆弱。
— 第四部分 肥尾分布简介 —
任何的肥尾分布都可以被表示为一个方差随机的高斯分布,比如时间序列分析中的异方差误差项就属于肥尾分布。假设我们将一个分布的E(x^2)固定,增大E(x^4)项使其肥尾,相当于将方差项“随机化”了,比如假设随机变量X满足:
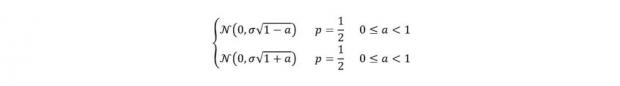
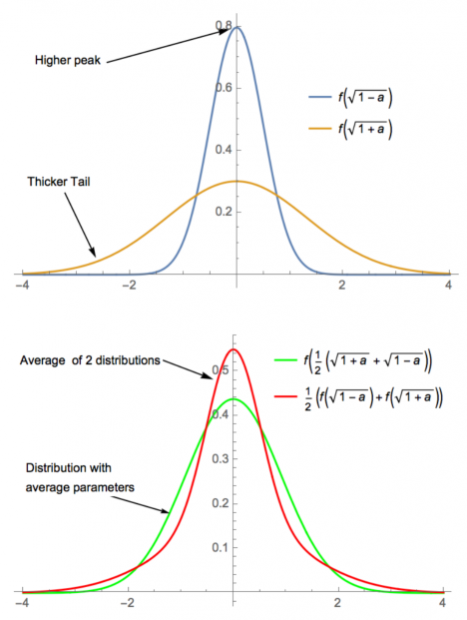
从特征函数可以求得该分布的方差为σ^2,四阶矩为〖3(a^2+1)σ〗^4>3,因此为厚尾分布。下图中直观展示了其厚尾特性,其中红线分布(两分布平均)的尾部厚于绿线分布(方差平均)的尾部:
肥尾的隧穿效应
对于任意一个分布来说,对尾部加厚必然会导致尖峰,而加厚部分的概率也自然来源于非尾部部分,导致分布的隧穿。对于随机变量X来说,概率密度函数为p(x),如果该分布是双尾分布,对于方差随机化的分布:
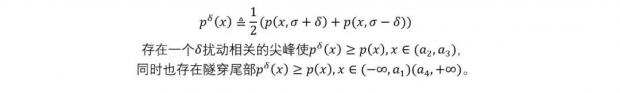
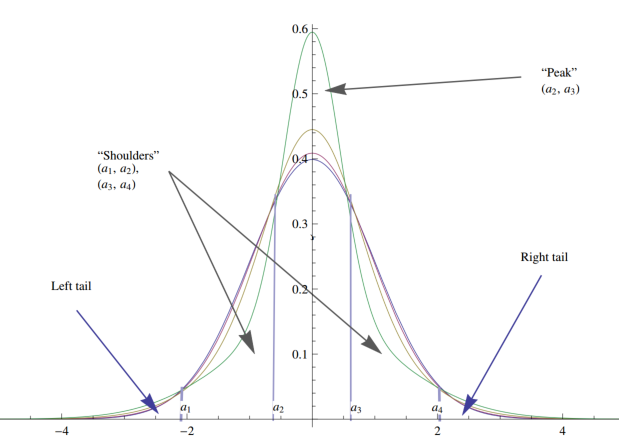


平均差和标准差

平均差相对标准差有如下几个优点:
平均差在衡量样本离散程度上更加稳定,标准差相当于用自身数据进行了一次加权
在金融应用(期权定价)中平均差的意义更大
对于部分分布方差无限,不存在标准差,但是存在平均差
无限矩
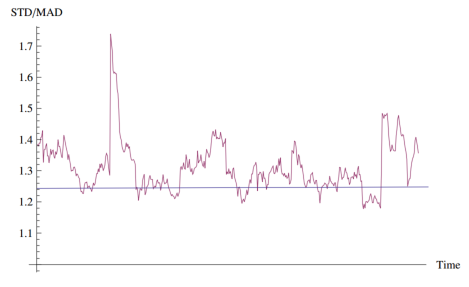
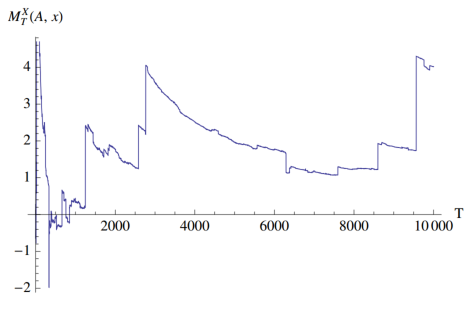
对于每个有限量样本来说,我们总是可以求得有限矩,比如样本均值和方差,但是对于分布本身来说矩并不一定有限,比如柯西分布的均值和方差并不存在。在这种情况下,每个不同的样本都会得到不同的矩,且增大样本并不会收敛。如下图所示,均值和方差在下一次跃变前会出现“伪收敛”。
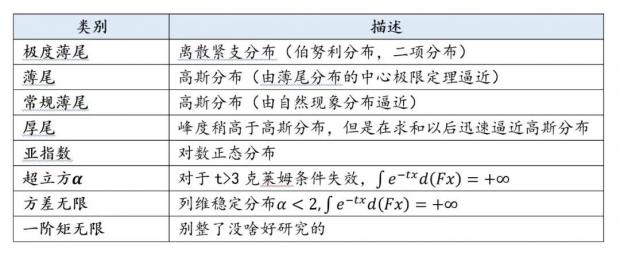
亚指数分布和幂律分布
在分布由极度薄尾(伯努利)到极度肥尾的过程中,我们通过矩的收敛情况将肥尾程度做如下分类。
之前我们所提到的平均斯坦和极端斯坦的界限就出现在亚指数地带,假定如下条件:

亚指数的尾部比指数分布的尾部更厚,而且亚指数分布无法通过矩母函数求矩,对于所有的ε>0:
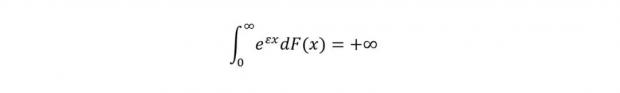
临界概率分布
根据尾部的极限特征,对于随机变量X我们可以进行如下定义:

幂律分布(帕累托分布)和尾部α

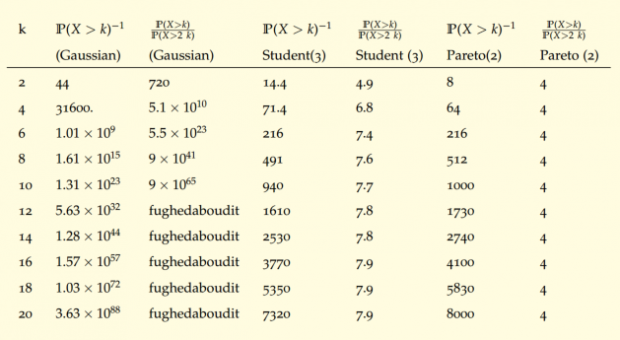
下表展示了高斯分布,学生T分布和帕累托分布的尾部特性,可以看到高斯分布的尾掉的很快,如果我们观测到一个很大的随机变量,几乎不可能再观测到该值2倍的结果。而对于学生T和帕累托分布则不然,翻倍的尾部值永远会以固定概率出现,不断打破人们对尾部风险的认知。

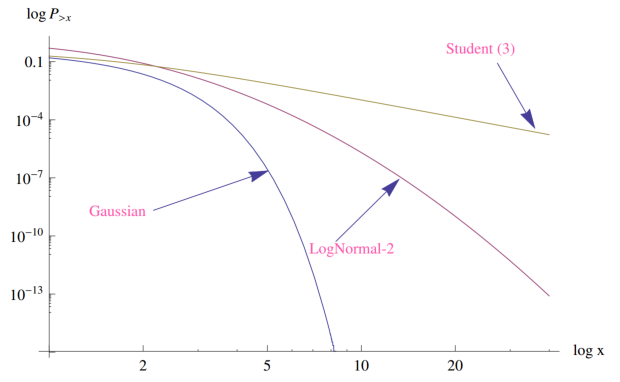
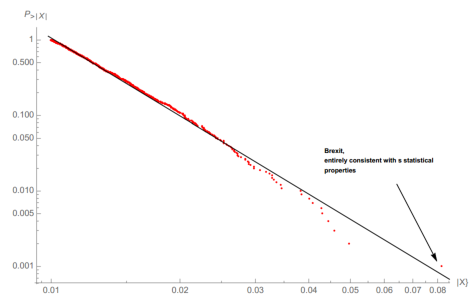
由此出发我们可以通过log-log图估计金融市场分布的尾部情况,此处要注意灰天鹅(对分布估计的不足),比如下图右下角的点为英国脱欧事件,一个极值点会极大地改变尾部α值。
幂律分布的特性:
不同随机变量混杂:幂律尾+薄尾=幂律尾,几个分布组合的尾部取决于最厚的尾
如果随机变量X尾部指数为α,则X^p的尾部指数为α/p
超级肥尾:对数帕累托分布
对于普通的幂律尾部,随着x不断增大,尾部概率在log-log图上最终会以直线的形式下降(斜率为-α),而对数帕累托尾部更加可怕,在log-log图中极限尾部斜率为0(不再下降),对数帕累托分布概率密度函数如下:
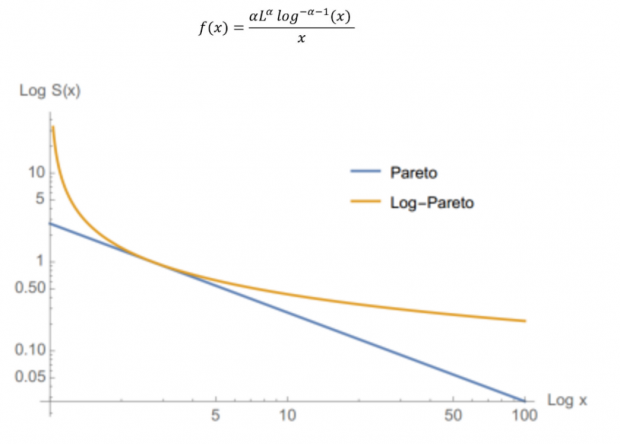
对于这种超级肥尾分布,自然所有矩都不存在。
多变量肥尾分布
对于多元分布来说,可以用协方差矩阵Σ将概率密度函数写成向量化的形式,比对对于n维高斯分布,其概率密度函数定义为:

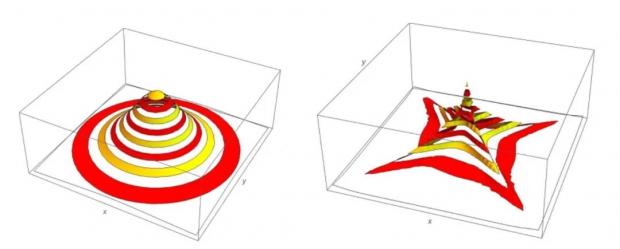
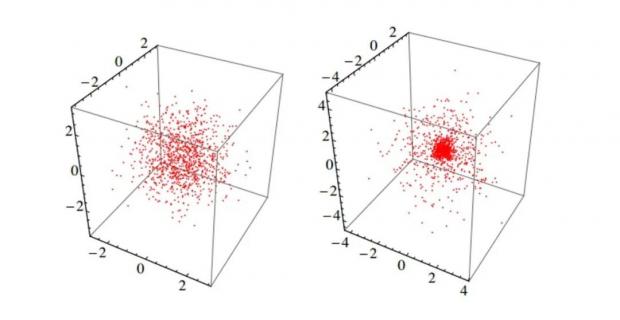
在肥尾分布方面一些单变量的结论仍然成立,比如分布的隧穿,肥尾分布的“尾部”和“中间”会更密集,而“肩部”的概率降低,如下图中随机变量分别满足三维薄尾分布(左)和肥尾分布(右)。

并不满足独立性条件,因此两肥尾变量独立(共同信息为0)时线性相关系数ρ不为0。
另外,对于方差无限的随机变量来说,在多变量联合分布中,其相关系数依然存在于[-1,1]之间,不过收敛很慢,对样本进行估计会呈现出极大误差。
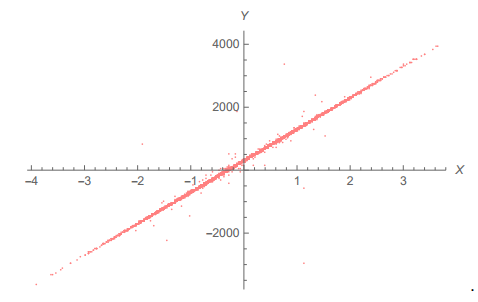
线性回归中的肥尾误差
在很多经济学研究中都会用到线性回归,并通过一个相对较高的R^2来表明模型具备解释性。但是在肥尾分布的世界中,如果我们用肥尾随机变量相对薄尾随机变量做回归,在小样本下很容易得到高R^2,带来统计上的失真。

特殊肥尾分布
我们之前讨论的都是单一模型的分布,并通过“随机化”方差实现了肥尾。如果把均值也随机化会如何呢?也即将完全不同的概率分布组合起来。在这样的多模型分布中,不同状态之间是阶跃式变化的,比如一个咖啡杯的状态分布,只有完好和破碎两种,并不存在“稍有破碎”这样的中间状态。在现实世界中,我们经常会看到类似的状态模型,比如战争-和平模型,两种状态下经济变量的分布截然不同(左),或者是债券的赔付模型,固定的利息支付可以看作是狄拉克函数,而一旦违约则赔付不确定(右)。
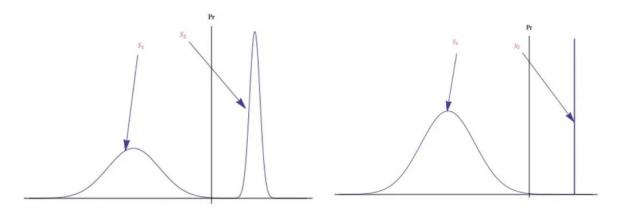

可以看到均值的拉开会降低峰度,而方差的拉开会提高峰度,两者互相竞争,此时通过峰度大小定义肥尾分布的传统方法不再有效。
双状态模型的例子有:
货币汇率(固定汇率制):维系或者脱钩,一旦脱钩就会发生大幅波动
企业并购:成功或者失败
职业选择:不同路径选择下的不同结果
冲突:战争与和平
— 第五部分 中数定律 —
在数学上,大数定律和中心极限定理共同解决的问题是:无穷个随机变量相加时其和的渐进性质如何。由此出发,一个更具现实意义的问题是“中数定律”:如果随机变量数目不到无穷,其和的性质会如何?
大数定律
大数定律描述的是当n趋于无穷时,n个独立同分布随机变量取平均值收敛于分布均值。这里收敛的模式有两种,一种是以分布形式收敛,对应弱大数定律,另一种是必然收敛,对应强大数定律。
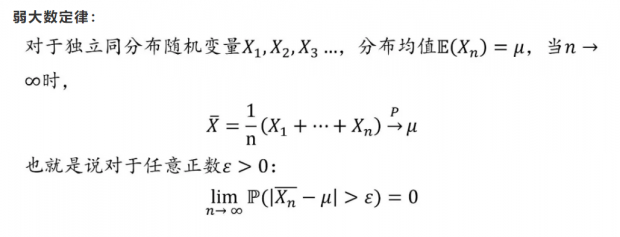

中心极限定理

如果放宽方差有限的条件,广义中心极限定理描述独立同分布随机变量的和分布满足稳定分布。
对于大数定律和中心极限定理,我们知道无论如何在n→∞时会收敛,但是当n<∞时不同分布收敛的速度可能有很大差异,因此需要对收敛速度进一步研究。
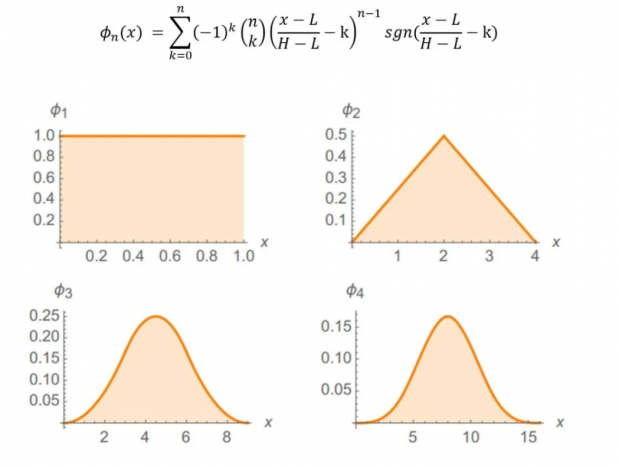
快速收敛:均匀分布
对于均匀分布来说,概率密度函数为一条直线,下方总面积为1。求和时收敛极快,只需要3个变量就会出现钟型曲线,假设均匀分布Xϵ[L,H],其和分布为:
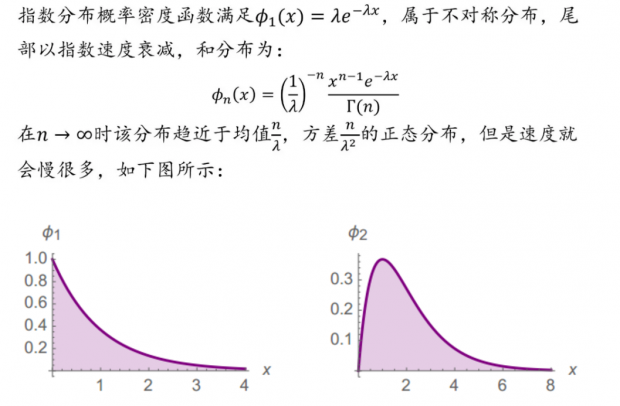
中速收敛:指数分布
指数分布概率密度函数满足ϕ_1 (x)=λe^(-λx),属于不对称分布,尾部以指数速度衰减,和分布为:
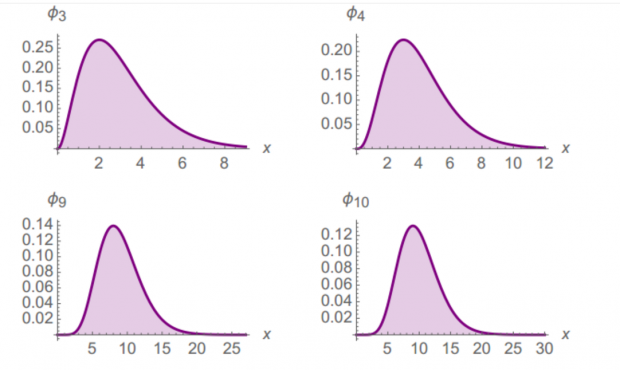
缓慢收敛:帕累托分布
高阶矩的大数定律
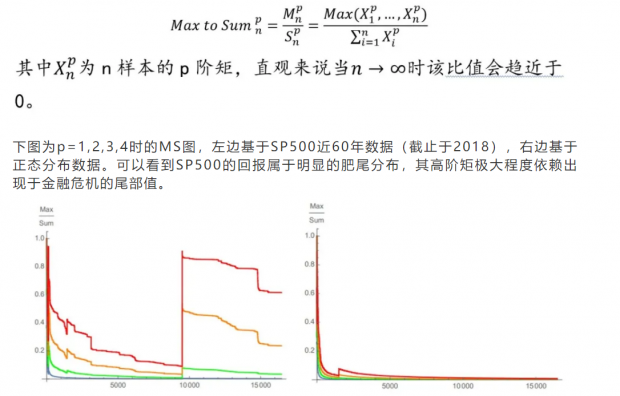
测试分布肥尾的一个办法是通过大数定律观察高阶矩的收敛性。如果分布的高阶矩存在,通过不断增加数据量,可以看到样本矩逐渐向理论值收敛。如果矩不存在则每组样本的值都会不同,增加数据量依然会看到值出现跃变。另外我们还可通过MS图(Max to Sum)来观察,即样本内矩极大值比所有矩之和,定义如下:
肥尾指标Kappa
之前我们讨论了不同程度的肥尾分布,而决策者通常面临的一个问题是:如果已有一个样本集,比如金融市场收益率,看上去是肥尾分布,我们需要多大的数据量才能得出有意义的统计结论?如果是高斯分布,我们用少量的数据就能有效的估计分布参数,但是如果是一个尾部α=2.1的帕累托分布呢,又或者2个自由度的学生T分布,这时多少数据量合适?
一般人们在比较肥尾程度时会采用高阶矩,比如峰度(如果存在的话),用其超过某个值的概率作为指标(尺度调整后),但是对于峰度不存在的极度厚尾则无能为力。这里提出一个新方法:考量在给定分布下额外数据能在多大程度上增加均值观测的稳定性?由此产生肥尾指标κ (Kappa)。κ可以有如下用途:
对不同分布的和分布进行比较,或是对同一分布不同数量的和分布比较
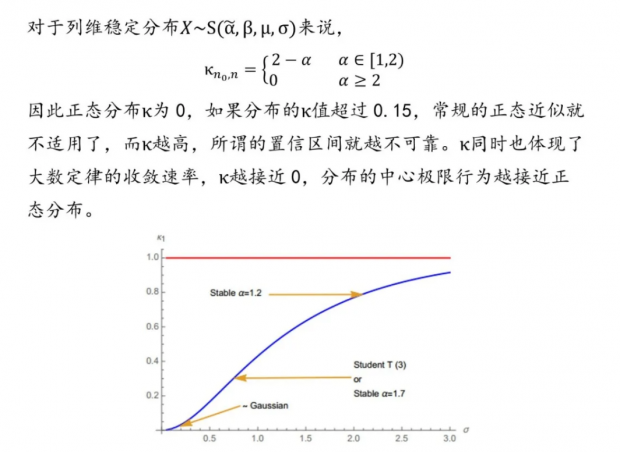
衡量一个分布在列维α稳定分布中的位置(正态分布是其中的一个特例)
定量比较大数定律下不同分布收敛的速度
比较两个完全不同分布的肥尾程度(只要分布一阶矩存在)
在研究中帮助推出蒙特卡洛模拟所需次数
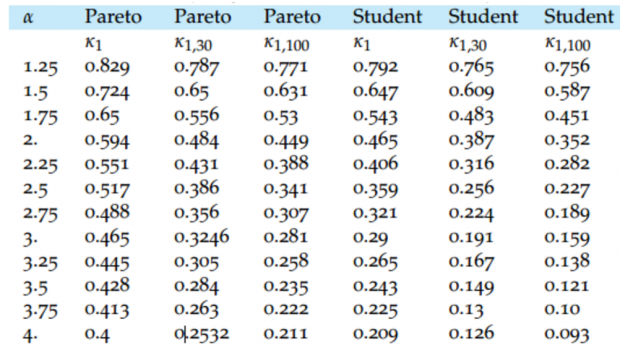

在这个式子中我们可以得到均值收敛到相同精度所需的样本数,比如对于3个自由度的学生T分布,两者比值为4,也就是说同样得到有效均值,正态分布需要30个数据点,而这样的学生T分布需要120个数据点。而对于α=3的单尾帕累托分布,则需要543个数据点。如果是α≈1.14的帕累托80/20分布,需要>10^9个数据点,也就是说,拟合这样的肥尾分布有限的几千上万个数据远远不够。
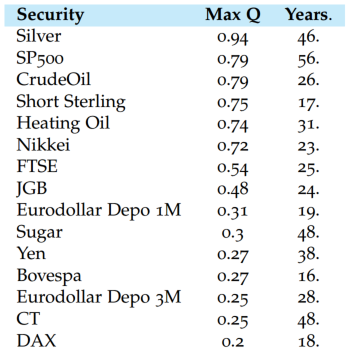
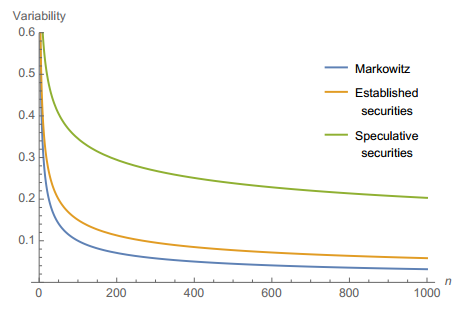
在金融领域,肥尾分布由于高κ带来大数定律和中心极限定理收敛较慢,会影响很多的现有的学术结论。比如对于Markowitz投资组合理论,分散化带来的好处就被大大降低了。投资组合理论中假设各个证券的收益率符合正态分布,在收益率互相独立时建立投资组合,组合波动率会随着证券加入飞快的降低。但是在收益率肥尾分布的假设下,根本无法用原来数量的证券来控制组合波动,投资者需要远远比理论更多的证券量。因此在实际市场中很多组合的波动远远高于理论,其关系如下图所示,为控制组合波动率实际需要的证券数量(绿线)远远高于投资者以为安全的数量(橙线),和Markowitz预测所需证券数量(蓝线)。
分布极端值和隐藏风险
在研究某分布的过程中,因为能得到的样本量总是有限,在尾部总会有一段分布遗失。这样一来过去的极值并不是一个预测未来极值的好指标。我们可以研究随机变量极大值的分布,来进一步理解肥尾分布样本下隐含的风险。

看不见的尾
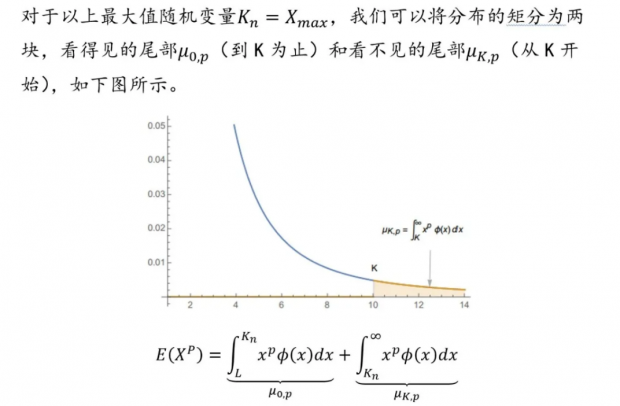

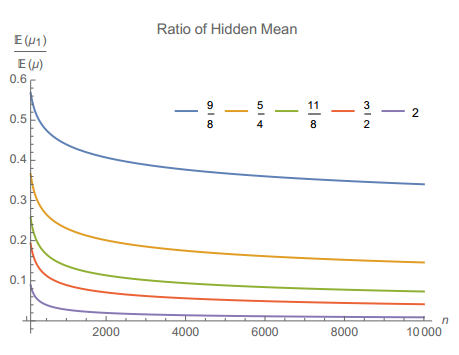
该比值随着α降低而升高,也就是说对越肥尾的分布,我们在有限样本下获得的信息偏差越大,“看不见的尾”甚至可以完全起主导作用。
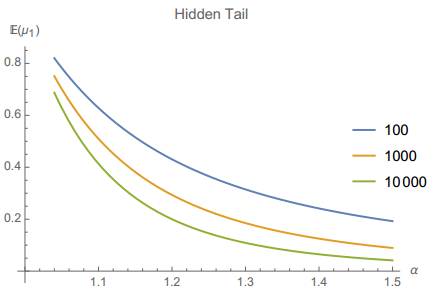
从这个角度出发,金融市场中看不见的尾会导致我们系统性的低估风险。一个典型的例子是CVAR这样的尾部风险指标(条件风险值)。实践中的CVAR往往由历史数据得出,但是历史数据会大大低估尾部均值,哪怕有“大量的”历史数据。对于美国股票市场来说,随着风险条件的提高,基于历史的CVAR会被低估5-70倍。
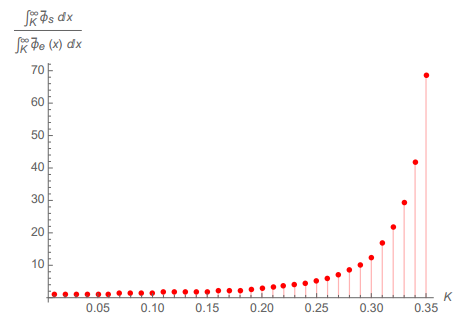
大偏差理论

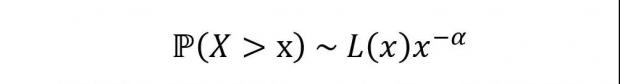
帕累托分布参数拟合
如果样本满足帕累托分布,要求解分布统计量时先进行参数拟合会极大提高精度,即先通过样本拟合尾部α值,假定分布满足:
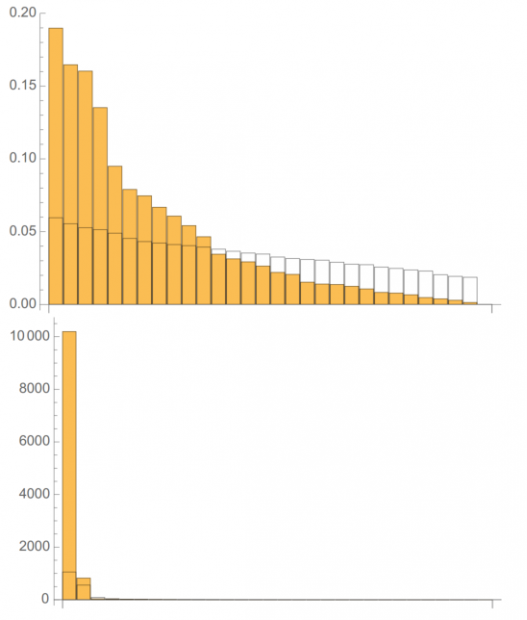
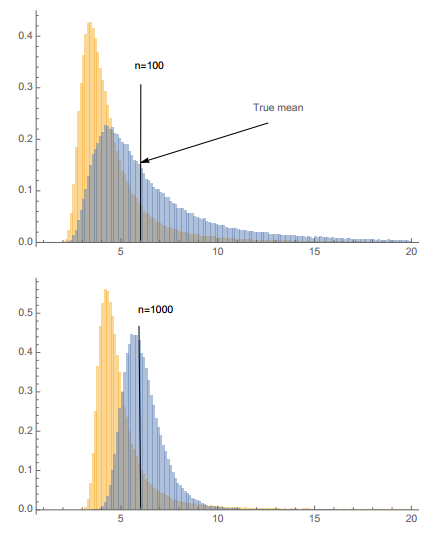
对α的估计满足倒gamma分布且迅速收敛到高斯分布,因此不需要大量观测就可以对分布进行有效逼近。从下图的蒙特卡洛模拟中可以看出,求解分布均值时,极大似然估计α后求解相对于直接求样本均值更有效。(每个分布代表10000次模拟,黄色为样本均值分布,蓝色为极大似然估计法均值分布,均值采样样本量分别为100和1000,黑色线为实际均值)
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}